
En muchas ocasiones, la instalación en las organizaciones de determinados productos de terceros puede suponer un auténtico quebradero de cabeza si lo que se quiere es poder tener trazabilidad desde todo de un único punto (como podría ser, por ejemplo, Kibana). ¿Te imaginas que todo esto fuera posible simplemente haciendo pooling de las trazas generadas? En el artículo de hoy veremos uno de estos casos, tomando como punto de inicio las trazas generadas por el Enterprise Integrator de WSO2 (aunque bien podría haber sido cualquier otro sistema), y veremos cómo podemos conectarlo todo con el sistema ELK (Elasticseach + Logstash + Kibana) a través del Filebeat. Por cierto, por si fuera de tu interés, aquí te dejo los enlaces a los primeros artículos de nuestros sensacionales cursos de Primeros pasos con WordPress e Introducción a Jenkins.
Tabla de contenidos
Introducción
WSO2 Enterprise Integrator es una plataforma de integración 100% open source que cumple con la gran mayoría de los escenarios de integración. Por su parte, Elastic Stack (ELK Stack) es un conjunto de productos (también open source) que permiten a sus usuarios publicar datos desde diversas fuentes y en diferentes formatos, pudiendo buscarlos, analizarlos y visualizarlos casi en tiempo real.

Pues bien, el servidor de WSO2 Enterprise Integrator puede ser configurado para generar trazas de log de distintos niveles, las cuales pueden ser utilizadas para auditoría y/o para que los administradores del sistema puedan monitorizar el estado del servidor. En el artículo de hoy, veremos cómo configurar Elastic Stack (ELK Stack) para monitorizar estas trazas fácilmente, sirviéndonos para ello de un sistema intermedio (Filebeat) que hará pooling de los archivos de log.

Instalación y Arranque de Componentes
Aparte del WSO2 Enterprise Integrator (versión 6.4.0) y los componentes del sistema ELK (Elasticsearch, Logstash y Kibana), para conectar todo el flujo será necesario instalar Filebeat. Obviaremos en este artículo la instalación de WSO2 EI (ya que daría para otro artículo completo), y nos centraremos en el resto de componentes, que preferiblemente deberían ser instalados en el siguiente orden para evitar problemas de dependencias.
1. Elasticsearch
En primer lugar, habrá que descargar Elasticsearch de «https://www.elastic.co/es/downloads/elasticsearch«. En nuestro caso, descargaremos la versión de Windows para 64 bits (elasticsearch-7.3.2-windows-x86_64.zip).

Después, descomprimimos el archivo en «C:\Program Files» (o donde se estime conveniente). Se recomienda renombrar la carpeta creada a «Elasticsearch». Por defecto, el programa no requiere ningún tipo de configuración concreta. En caso de requerirlo, editaríamos el archivo «config/elasticsearch.yml».
Y ya estaría todo. Solo quedaría lanzar script de inicio de Elasticsearch:
| C:\Program Files\Elasticsearch\bin\elasticsearch.bat |
2. Logstash
En primer lugar, descargaremos Logstash de «https://www.elastic.co/es/downloads/logstash«. En nuestro caso, descargaremos el archivo zip (logstash-7.3.2.zip).

Una vez descargado el archivo, lo descomprimiremos en «C:\Program Files» (o donde se estime conveniente). Se recomienda renombrar la carpeta creada a «Logstash».
Ahora, en la carpeta «config», copiaremos el archivo «logstash-sample.conf» y lo renombraremos a «logstash.conf». Este será el archivo de configuración que utilizaremos al lanzar Logstash, para lo cual lo podemos dejar tal cual (configuración por defecto), o bien una configuración típica podría ser:
|
input { filter { output { |
En este archivo, estamos configurando un pipeline, de manera que escucharemos en el puerto 5044 todo lo que llegue de Filebeat, y redirigiremos a Elasticsearch en el puerto 9200 (su puerto por defecto, si no lo hemos cambiado).
Por último, lanzamos el script de inicio de Logstash:
| C:\Program Files\Logstash\bin\logstash.bat -f ..\config\logstash.conf |
Puede que la ejecución de un error del tipo:
| Error: no se ha encontrado o cargado la clase principal Files\Logstash\logstash-core\lib\jars\animal-sniffer-annotations-1.14.jar;C:\Program. |
En tal caso, habría que editar el archivo «bin/logstash.bat».
- Buscar la línea donde pone:
| %JAVA% %JAVA_OPTS% -cp «%CLASSPATH%» org.logstash.Logstash %* |
- Y cambiar por:
| %JAVA% %JAVA_OPTS% -cp %CLASSPATH% org.logstash.Logstash %* |
3. Filebeat
En primer lugar, descargaremos Filebeat de «https://www.elastic.co/es/downloads/beats/filebeat«. En nuestro caso, descargaremos la versión de Windows para 64 bits (filebeat-7.3.2-windows-x86_64.zip).

Una vez descargado el archivo, lo descomprimiremos en «C:\Program Files» (o donde se estime conveniente). Se recomienda renombrar la carpeta creada a «Filebeat».
Ahora, editaremos archivo de configuración (filebeat.yml), de manera que acabe teniendo las siguientes líneas:
|
#=========================== Filebeat inputs ============================= filebeat.inputs: # Each – is an input. Most options can be set at the input level, so – type: log # Change to true to enable this input configuration. # Paths that should be crawled and fetched. Glob based paths. … ### Multiline options # Multiline can be used for log messages spanning multiple lines. This is common # The regexp Pattern that has to be matched. The example pattern matches all lines starting with [ # Defines if the pattern set under pattern should be negated or not. Default is false. # Match can be set to «after» or «before». It is used to define if lines should be append to a pattern #================================ Outputs ===================================== # Configure what output to use when sending the data collected by the beat. #————————– Elasticsearch output —————————— # Optional protocol and basic auth credentials. #—————————– Logstash output ——————————– … |
Nótese que, para que el flujo pase por Logstash, es necesario comentar el output que hace referencia a Elasticsearch y descomentar el que hace referencia a Logstash (ya que, en otro caso, el script de arranque dará un error). Además, si no queremos que la trazas de java (u otras) aparezcan divididas, hemos de configurar también el multiline.
Por otro lado, como vemos, hemos puesto el path con el valor «- C:\Program Files\WSO2\Enterprise Integrator\6.4.0\repository\logs\wso2carbon.log», de manera que se haga pooling de todo lo escrito en el archivo «wso2carbon.log». Evidentemente, todo dependerá de los archivos sobre los que queremos hacer pooling, pues también podríamos indicar que se hiciera pooling de todo el directorio simplemente cambiando «wso2carbon.log» por «*».
Por último, para lanzar el demonio de Filebeat, desde una interfaz de comandos ejecutaremos:
| C:\Program Files\Filebeat\filebeat.exe |
Si lo que queremos es ver la salida por pantalla, en lugar de lo anterior ejecutaremos:
| C:\Program Files\Filebeat\filebeat.exe -c filebeat.yml -e -d «*» |
4. Kibana
En primer lugar, descargaremos Kibana de «https://www.elastic.co/es/downloads/kibana«. En nuestro caso, descargaremos la versión de Windows para 64 bits (kibana-7.3.2-windows-x86_64.zip).

Una vez descargado el archivo, lo descomprimiremos en «C:\Program Files» (o donde se estime conveniente). Se recomienda renombrar la carpeta creada a «Kibana».
Ahora, editaremos el archivo de configuración (config/kibana.yml), descomentando las siguientes líneas:
| server.port: 5601 server.host: «localhost» elasticsearch.hosts: [«http://localhost:9200»] |
El valor de la propiedad «elasticsearch.hosts» deberá coincidir con la URL donde tengamos desplegado nuestro Elasticsearch.
Por último, quedaría lanzar el script de inicio de Kibana:
| C:\Program Files\Kibana\bin\kibana.bat |
Nota: hay que ejecutarlo como administrador, ya que de lo contrario daría el error «EPERM: operation not permitted».
Por último, para comprobar que todo está correcto, se puede acceder a la consola de Kibana en «http://localhost:5601». Evidentemente, esta URL dependerá del valor que le hayamos puesto a la propiedad «server.port» en el archivo de configuración.
Funcionamiento del Sistema
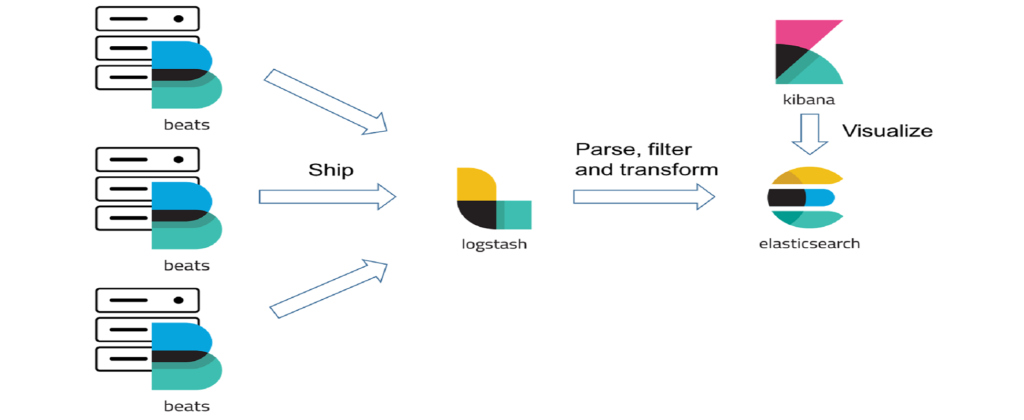
Una vez instalados todos los componentes, el sistema funcionará de la siguiente manera:
- Se hace log sobre el archivo «wso2carbon.log» del WSO2 Enterprise Integrator.
- Filebeat, que está haciendo pooling en dicho fichero, obtiene la información, y la envía al servidor Logstash.
- Logstash recibe la información, la transforma (dependiendo de cómo tengamos definido el pipeline que escucha por el puerto configurado) y la envía a Elasticsearch.
- Elasticsearch, que no es más que una base de datos indexada, almacena la información recibida.
- Kibana va realizando queries sobre el servidor Elasticsarch que tenga configurado, y muestra la información en sus cuadros de mando.
Otra opción interesante podría consistir en añadir dentro del flujo algún sistema intermedio de buffering, como podría ser un servidor Kafka u otros (Redis, Rabbit MQ, etc.).



