
Si en un artículo anterior vimos detenidamente qué es Maven, en éste estudiaremos más a fondo si cabe uno de los sistemas de control de versiones más extendidos de la actualidad: Git. En particular, veremos qué es, las ventajas de utilizarlo, su funcionamiento y, por último, las órdenes básicas que podemos ejecutar. Terminaremos el artículo conociendo Github y su relación con el propio Git.
¿Qué es Git?
Para entender perfectamente qué es Git, en primer lugar hemos de plantearnos 2 preguntas:
- ¿Qué es el control de versiones?
- ¿Qué es un sistema de control de versiones?
El control de versiones es una de las tareas fundamentales para la administración de un proyecto de desarrollo de software en general. Surge de la necesidad de mantener y llevar control del código que vamos programando, conservando sus distintos estados. Es absolutamente necesario para el trabajo en equipo, pero resulta útil incluso a desarrolladores independientes.
Aunque trabajemos solos, sabemos más o menos cómo surge la necesidad de gestionar los cambio entre distintas versiones de un mismo código. En cuanto a equipos de trabajo se refiere, seguro que la mayoría hemos experimentado las limitaciones y problemas en el flujo de trabajo cuando no se dispone de una herramienta como Git: machacar los cambios en archivos hechos por otros componentes del equipo, incapacidad de comparar de manera rápida dos códigos, para saber los cambios que se introdujeron al pasar de uno a otro, etc. Además, en todo proyecto surge la necesidad de trabajar en distintas ramas al mismo tiempo.

Para facilitarnos la vida en estas actividades, surgen los diversos sistemas de control de versiones («Git», «Subversion», «CVS», etc.), que sirven para controlar las versiones de un software y que deberían ser una obligatoriedad en cualquier desarrollo. Estas herramientas nos ayudan en muchos ámbitos fundamentales:
- Comparar el código de un archivo, de modo que podamos ver las diferencias entre versiones.
- Restaurar versiones antiguas.
- Fusionar cambios entre distintas versiones.
- Trabajar con distintas ramas de un proyecto.
En definitiva, con estos sistemas podemos crear y mantener repositorios de software que conservan todos los estados por el que va pasando la aplicación a lo largo del desarrollo del proyecto. Además, almacenan las personas que enviaron los cambios, las ramas de desarrollo que fueron actualizadas o fusionadas, etc.
Entrando más en detalle, comentar que tenemos dos tipos de sistemas de control de versiones:
- Centralizados: hay un servidor que mantiene el repositorio y en el que cada programador mantiene en local únicamente aquellos archivos con los que está trabajando en un momento dado. Ejemplos de este tipo de sistemas son Subversion y CVS.
- Distribuidos: cada uno de los integrantes del equipo mantiene una copia local del repositorio completo. Al disponer de un repositorio local, puedo hacer commit (enviar cambios al sistema de control de versiones) en local, sin necesidad de estar conectado a Internet o a cualquier otra red. Git es un sistema de este tipo.
Tanto sistemas distribuidos como centralizados tienen ventajas e inconvenientes comparativas entre los unos y los otros. Los centralizados son un poco más lentos y pesados, pero por contra permiten definir un número de versión en cada una de las etapas de un proyecto (en los distribuidos, cada repositorio local podría tener diferentes números de versión). Por otro lado, en los centralizados existe un mayor control del desarrollo por parte del equipo, aunque los distribuidos, como veremos, permiten trabajar en cualquier momento y lugar.

Y llegamos por fin a la pregunta que queríamos responder: ¿qué es Git? Como ya sabemos, es un sistema de control de versiones distribuido. Fue diseñado por Linus Torvalds, pensando en la eficiencia y la confiabilidad del mantenimiento de versiones de aplicaciones cuando éstas tienen un gran número de archivos de código fuente. Es de código abierto, y su propósito es llevar registro de los cambios en archivos y coordinar el trabajo que varias personas realizan sobre archivos compartidos.

Por otro lado, Git es multiplataforma, por lo que puedes usarlo y crear repositorios locales en todos los sistemas operativos más comunes (Windows, Linux, Mac o Solaris). Además, existen multitud de GUIs (Graphical User Interface o Interfaz de Usuario Gráfica) para trabajar con Git a golpe de ratón; no obstante, para el aprendizaje se recomienda usarlo con línea de comandos (mediante la llamada «Git Bash»), de modo que puedas dominar el sistema desde su base, en lugar de estar aprendiendo a usar un programa determinado.

¿Por qué utilizar Git?
Git nos proporciona las herramientas para desarrollar un trabajo en equipo de manera inteligente y rápida (y por «trabajo» nos referimos a algún software o página que implique código el cual necesitemos hacerlo con un grupo de personas).

Algunas de las características y ventajas más relevantes de Git son:
- Fuerte apoyo al desarrollo no lineal y, por ende, rapidez en la gestión de ramas y mezclado de diferentes versiones. Git incluye herramientas específicas para navegar y visualizar un historial de desarrollo no lineal. Una presunción fundamental en Git, es que un cambio será fusionado mucho más frecuentemente de lo que se escribe originalmente, conforme se pasa entre varios programadores que lo revisan.
- Gestión distribuida. Git le da a cada programador una copia local del historial del desarrollo entero, y los cambios se propagan entre los repositorios locales. Los cambios se importan como ramas adicionales y pueden ser fusionados en la misma manera que se hace con la rama local.
- Los almacenes de información pueden publicarse por HTTP, FTP, rsync o mediante un protocolo nativo, ya sea a través de una conexión TCP/IP simple o a través de cifrado SSH. Git también puede emular servidores CVS, lo que habilita el uso de clientes CVS pre-existentes y módulos IDE para CVS pre-existentes en el acceso de repositorios Git.
- Los repositorios Subversion y svk se pueden usar directamente con git-svn.
- Gestión eficiente de proyectos grandes (dada la rapidez de gestión de diferencias entre archivos), además de otras mejoras de optimización de velocidad de ejecución.
- Todas las versiones previas a un cambio determinado, implican la notificación de un cambio posterior en cualquiera de ellas a ese cambio (denominado autenticación criptográfica de historial).
- Resulta algo más caro trabajar con ficheros concretos frente a proyectos, pero mejora el trabajo con afectaciones de código que concurren en operaciones similares en varios archivos.
- Los renombrados se trabajan basándose en similitudes entre ficheros, aparte de nombres de ficheros, pero no se hacen marcas explícitas de cambios de nombre con base en supuestos nombres únicos de nodos de sistema de ficheros, lo que evita posibles y desastrosas coincidencias de ficheros diferentes en un único nombre.
- Realmacenamiento periódico en paquetes (ficheros). Esto es relativamente eficiente para escritura de cambios y relativamente ineficiente para lectura si el reempaquetado (con base en diferencias) no ocurre cada cierto tiempo.
Otra de las ventajas fundamentales de Git es que, al ser un sistema de control de versiones distribuido, la mayoría de las operaciones sólo necesitan archivos y recursos locales para operar, con lo que éstas parecen prácticamente inmediatas. Por ejemplo, para navegar por la historia del proyecto, Git no necesita salir al servidor para obtener la historia y mostrártela, simplemente la lee directamente de tu base de datos local.

Todo lo anterior también significa que hay muy poco que no puedas hacer si estás desconectado o sin VPN. Por ejemplo, si te subes a un avión o a un tren y quieres trabajar un poco, puedes confirmar tus cambios felizmente hasta que consigas una conexión de red para subirlos; si te vas a casa y no consigues que tu cliente VPN funcione correctamente, puedes seguir trabajando. En muchos otros sistemas, esto es imposible o muy costoso.

Por otro lado, todo en Git es verificado mediante una suma de comprobación (checksum en inglés) antes de ser almacenado, y es identificado a partir de ese momento mediante dicha suma. Esto significa que es imposible cambiar los contenidos de cualquier archivo o directorio sin que Git lo sepa. El mecanismo que usa Git para generar esta suma de comprobación se conoce como «hash SHA-1», una cadena de 40 caracteres hexadecimales (0-9 y a-f) que se calcula en base a los contenidos del archivo o estructura de directorios (un ejemplo podría ser «24b9da6552254567aa493b52f8432cd6d3b00373»).

Funcionamiento
La principal diferencia entre Git y cualquier otro VCS (Subversion y compañía incluidos) es cómo Git modela sus datos. Conceptualmente, la mayoría de los demás sistemas almacenan la información como una lista de cambios en los archivos. Estos sistemas (CVS, Subversion, Perforce, Bazaar, etc.) modelan la información que almacenan como un conjunto de archivos y las modificaciones hechas sobre cada uno de ellos a lo largo del tiempo

Por su parte, Git modela sus datos más como un conjunto de instantáneas de un mini sistema de archivos. Cada vez que confirmas un cambio, o guardas el estado de tu proyecto en Git, él básicamente hace una foto del aspecto de todos tus archivos en ese momento, y guarda una referencia a esa instantánea.
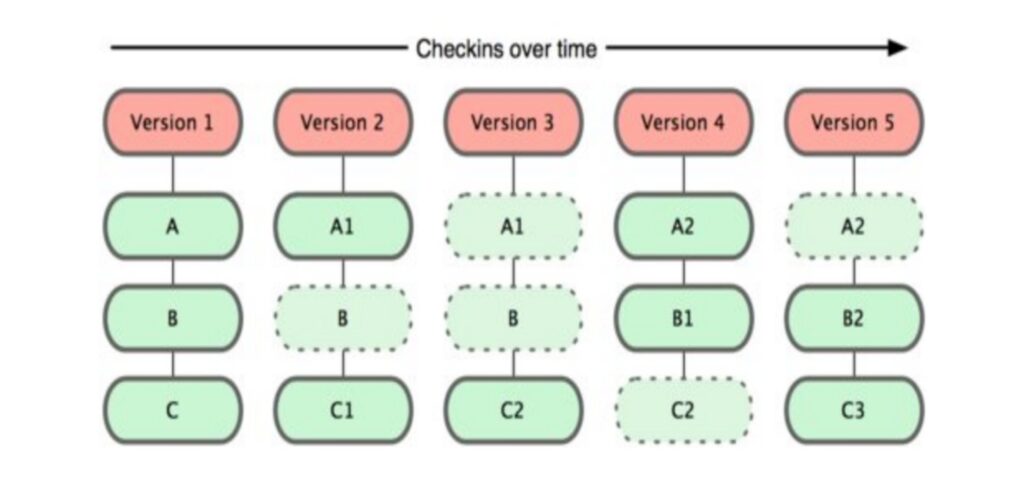
Git tiene tres estados principales en los que se pueden encontrar tus archivos:
- Confirmado (committed/unmodified): los datos están almacenados de manera segura en tu base de datos local.
- Modificado (modified): has modificado el archivo pero todavía no lo has confirmado a tu base de datos.
- Preparado (staged): has marcado un archivo modificado en su versión actual para que vaya en tu próxima confirmación.
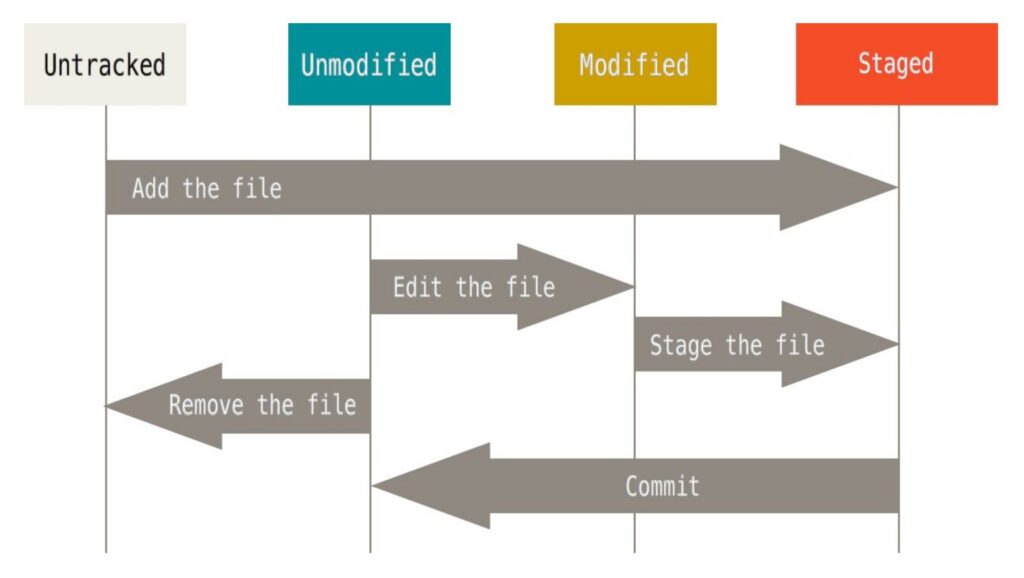
Esto nos lleva a las tres secciones principales de un proyecto de Git:
- Directorio de Git (Git directory): donde Git almacena los metadatos y la base de datos de objetos para tu proyecto. Es la parte más importante de Git, y es lo que se copia cuando clonas un repositorio desde otro ordenador.
- Directorio de trabajo (working directory): es una copia de una versión del proyecto. Estos archivos se sacan de la base de datos comprimida en el directorio de Git, y se colocan en disco para que los puedas usar o modificar.
- Área de preparación (staging area): archivo sencillo, generalmente contenido en tu directorio de Git, que almacena información acerca de lo que va a ir en tu próxima confirmación. A veces se le denomina «índice» (Index), pero se está convirtiendo en estándar el referirse a ella como el «área de preparación».

Por otro lado, tenemos el HEAD, que apunta al último commit realizado. La mayoría de las veces apuntará al último commit de tu rama actual, pero no tiene por qué ser así.
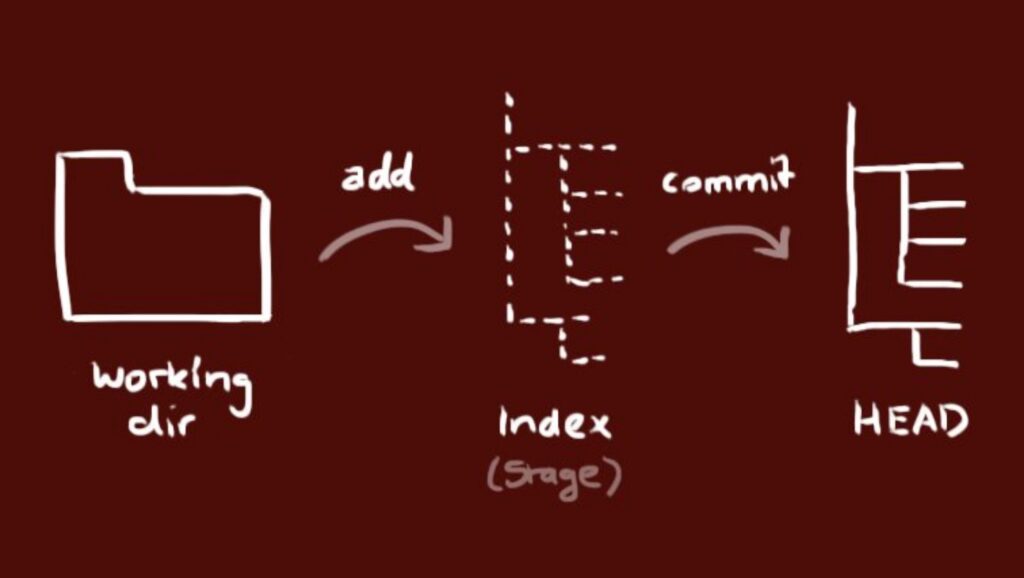
El flujo de trabajo básico en Git es algo así:
- Modificas una serie de archivos en tu directorio de trabajo.
- Preparas los archivos, añadiendolos a tu área de preparación.
- Confirmas los cambios, lo que toma los archivos tal y como están en el área de preparación, y almacena esas instantáneas de manera permanente en tu directorio de Git.
Si una versión concreta de un archivo está en el directorio de Git, se considera confirmada («committed»). Si ha sufrido cambios desde que se obtuvo del repositorio, pero ha sido añadida al área de preparación, está preparada («staged»). Por último, si ha sufrido cambios desde que se obtuvo del repositorio, pero no se ha preparado, está modificada («modified»).
Cada desarrollador o equipo de desarrollo puede hacer uso de Git de la forma que le parezca mas conveniente. Sin embargo, una buena práctica sería utilizar los siguientes 4 tipos de ramas:
- Master: rama principal. Contiene el repositorio que se encuentra publicado en producción, por lo que debe estar siempre estable.
- Development: rama sacada de master. Es la rama de integración, y todas las nuevas funcionalidades se deben integrar en esta rama. Luego que se realice la integración y se corrijan los errores (en caso de haber alguno), es decir que la rama se encuentre estable, se puede hacer un merge de development sobre la rama master.
- Features: cada nueva funcionalidad se debe realizar en una rama nueva, específica para esa funcionalidad. Estas se deben sacar de development. Una vez que la funcionalidad esté desarrollada, se hace un merge de la rama sobre development, donde se integrará con las demás funcionalidades.
- Hotfix: bugs que surgen en producción, por lo que se deben arreglar y publicar de forma urgente. Es por ello, que son ramas sacadas de master. Una vez corregido el error, se debe hacer un merge de la rama sobre master. Al final, para que no quede desactualizada, se debe realizar el merge de master sobre development.

Las ramas son utilizadas para desarrollar funcionalidades aisladas unas de otras. La rama master es la rama «por defecto» cuando creas un repositorio. La idea es ir creando nuevas ramas durante el desarrollo y fusionarlas a la rama principal cuando se haya terminado.
Órdenes básicas
Como comentábamos, existen diversas interfaces gráficas para interactuar con Git. No obstante, siempre resulta adecuado y conveniente conocer las órdenes básicas de Git para trabajar con la herramienta directamente y no depender de ninguna de estas interfaces.

En el siguiente listado podemos ver las órdenes más importantes que podemos ejecutar desde la línea de comandos:
- git add <nombre_archivo>: comienza a trackear el archivo “nombre_archivo” (con «.» añades todos los archivos del directorio, y con «*» lo añades todo).
- git add -i: permite agregar archivos de forma interactiva.
- git branch: lista todas las ramas locales.
- git branch -a: lista todas las ramas locales y remotas.
- git branch -d <nombre_rama>: elimina la rama local con el nombre “nombre_rama”.
- git checkout <nombre_rama>: salta sobre la rama «nombre_rama».
- git checkout — <filename>: reemplaza los cambios en tu directorio de trabajo con el último contenido de HEAD. Los cambios que ya han sido agregados al Index, así como también los nuevos archivos, se mantendrán sin cambio.
- git checkout -b <nombre_rama_nueva>: crea una rama con el nombre “nombre_rama_nueva” a partir de aquella en la que te encuentres parado, y luego salta sobre la rama nueva.
- git checkout -t origin/<nombre_rama>: si existe una rama remota de nombre “nombre_rama”, al ejecutar este comando se crea una rama local con el nombre “nombre_rama” para hacer un seguimiento de la rama remota con el mismo nombre.
- git clone </path/to/repository>: crea una copia local del repositorio. Si se utiliza un servidor remoto, habrá que usar «git clone <username@host:/path/to/repository>».
- git commit -am «<mensaje>»: confirma los cambios realizados. El “mensaje” generalmente se usa para asociar al commit una breve descripción de los cambios realizados. Ahora los archivos están incluídos en el HEAD, pero aún no en tu repositorio remoto.
- git diff <source_branch> <target_branch>: permite revisar los cambios antes de fusionarlos.
- git fetch: descarga los cambios realizados en el repositorio remoto.
- git init: inicia un repositorio vacío en una carpeta específica.
- git log: muestra un registro de los commits realizados.
- git merge <nombre_rama>: fusiona la rama «nombre_rama» a tu rama activa.
- git pull: unifica los comandos fetch y merge en un único comando (actualiza tu repositorio local al commit más nuevo).
- git push origin <nombre_rama>: sube los cambios desde el branch local origin al branch “nombre_rama”.
- git remote add origin <server>: conecta tu repositorio local a un repositorio remoto si no has clonado un repositorio ya existente. Ahora podrás subir tus cambios al repositorio remoto seleccionado.
- git remote prune origin: actualiza tu repositorio remoto en caso que algún otro desarrollador haya eliminado alguna rama remota.
- git reset –hard HEAD: elimina los cambios realizados que aún no se hayan hecho commit.
- git reset –hard origin/master: deshace todos los cambios locales y commits (es necesario hacer antes «git fetch origin», para traer la última versión del servidor y apuntar a tu copia local principal).
- git revert <hash_commit>: revierte el commit realizado, identificado por el “hash_commit”.
- git status: muestra el estado actual de la rama, como los cambios que hay sin commitear.
- git tag <version> <commit_id>: crea la etiqueta «version» asociada al commit «commit_id». Se recomienda crear etiquetas para cada nueva versión publicada de un software.
- gitk: ejecuta la interfaz gráfica por defecto.
GitHub
GitHub (github.com) es un servicio para alojamiento de repositorios de software gestionados por el sistema de control de versiones Git. En definitiva, GitHub es un sitio web pensado para hacer posible el compartir el código de una manera más fácil y al mismo tiempo darle popularidad a la herramienta de control de versiones en sí, que es Git.

Cabe destacar que GitHub es un proyecto comercial, a diferencia de la herramienta Git (que es un proyecto de código abierto). No obstante, en GitHub es gratuito alojar proyectos Open Source, lo que ha posibilitado que el número de proyectos no pare de crecer, y que en estos momentos haya varios millones de repositorios y usuarios trabajando con la herramienta.

Pero ojo, hay que tener claro que, al ser Git un sistema de control de versiones distribuido, no necesito GitHub u otro sitio de alojamiento del código para usar Git. Es decir, simplemente con tener Git instalado en mi ordenador, tengo un sistema de control de versiones completo, perfectamente funcional, para hacer todas las operaciones que necesito para el control de versiones. Eso sí, usar GitHub nos permite muchas facilidades, sobre todo a la hora de compartir código fuente, incluso con personas de cualquier parte del mundo a las que ni conoces.

Por otro lado, GitHub se ha convertido en una herramienta para los reclutadores de empleados, que revisan nuestros repositorios para saber en qué proyectos contribuimos y qué aportaciones hemos realizado. Por ello, hoy resulta importante para los programadores no solo estar en GitHub sino además mantener un perfil activo.


